
10.1-10.2 Principal Component Analysis
PCA(Principle Component Analysis)
차원 축소
- 차원 축소하는 이유
- 데이터에는 중요부분과 중요하지 않은 부분 즉, noise가 존재. 노이즈는 데이터에서 정보를 얻을 때 방해가 되는 부분이고 고로, 제거해야한다. 머신러닝 과정에서 불필요한 노이즈를 제거하는 것이 중요.
이 때 노이즈를 제거할 때 쓰는 방법이 차원 축소(dimension reduction)이다. - 차원의 저주를 해결할 수 있다.
- 차원의 저주란, 데이터의 ‘차원’이 커질수록 해당 차원을 표현하기 위해 필요한 데이터가 기하급수적으로 많아짐을 의미한다. 1차원 공간에 데이터 표현 공간이 0부터 10까지 있다고 하면, 해당 공간에는 10개의 데이터가 포함될 수 있다.
이 2차원 평면만 되어도, 공간을 채우는데 100개의 데이터가 필요하고,
3차원 공간을 채우는데에는 1000개의 데이터가 필요하다. - 이는 데이터셋의 차원이 클수록 해당 데이터 공간을 적절히 표현하지 못하여 오버피팅될 확률이 높아진다.
- 데이터에는 중요부분과 중요하지 않은 부분 즉, noise가 존재. 노이즈는 데이터에서 정보를 얻을 때 방해가 되는 부분이고 고로, 제거해야한다. 머신러닝 과정에서 불필요한 노이즈를 제거하는 것이 중요.
- ‘고양이’라는 인식을 하기위해 고양이를 직접 보지 않고 인식할 수 있다. 바로 2차원인 고양이의 ‘그림자’를 보고 인식하는 것이다.
- 3차원의 ‘고양이’라는 정보를 얻어내는 데에 2차원의 데이터만으로 충분하다라는 것!(3->2)
- 그러나, 그림자는 햇빛의 각도에 따라 변하는데, 너무 짧거나 길면 고양이라고 인식할 확률이 낮아진다.
- 차원 축소는 주어진 데이터의 ‘정보 손실을 최소화’하면서 줄이는 것이 핵심이다.
- 이러한 측면에서, 차원 축소는 '특징'을 '추출'한다는 것과 비슷하게 생각할 수 있다.
- ‘특징’ 즉, 두드러진 면, salient, significant part를 찾는 것과 같다.
- 고양이의 ‘그림자’(2차원 데이터)는 고양이의 중요 ‘특징’을 포함해야 한다. 고양이라고 판단할 수 있을 법한 정보를 포함해야한다는 것.
- 접근 방식
- 1) 비지도 학습 차원 축소: 주성분 분석(Principal Computer Analysis)
- 2) 지도 학습 차원 축소: 선형 판별 분석(Linear Discriminant Analysis)
PCA(주성분 분석)

- 정의: 여러 feature가 통계적으로 서로 ‘상관관계’가 ‘없도록’ 변환시키는 방법
- 특성:
- feature간 상관관계를 기반으로 데이터의 특성을 파악.
- 주성분 분석은 only 공분산행렬(covariance matrix)에만 영향 받는다.
- 공분산 행렬의 대각원소 = 각 피처의 분산
- ex) covmat X의 원소 x11 은 feature x1의 분산
- 공분산행렬의 고유값과 고유벡터를 구한다.
- 고유값: ‘고유 벡터 / 분산’의 크기
- 고유벡터: ‘분산’의 방향
- ‘분산’의 크기가 큰, 즉 고유값이 큰 해당 고유 벡터에 기존 데이터를 ‘투영’하면 새로운 데이터, '주성분 벡터'를 구할 수 있다.
- yi = Xei , where yi is ith 주성분 벡터, ei is ith 고유 벡터
- 구한 ‘주성분 벡터’간의 공분산을 구하면 0
- 즉, 서로 uncorrelated
- 즉, 서로 직교(orthogonal)
- 차원 축소 전, 공분산 행렬을 구하면, feature간 상관관계가 존재할 확률이 높음
PCA를 통해 차원 축소를 한 후, 주성분 벡터는 서로 uncorrelated - Eigen value를 모두 더하면 데이터 셋의 전체 변동성
- ith EV / Total sum of EV = Explained Variance = 해당 EV가 전체 변동성의 크기 중 어느 정도를 설명하는지 알 수 있음
PCA 알고리즘
(0) 데이터 셋 준비
(1) 데이터 셋을 피처별로 표준화(평균 빼고 분산으로 나누기)
(2) feature data의 행렬로부터 covariance matrix 구하기
(3) 구한 cov mat의 eigen value, eigen vector 구하기
(4) eigen value 큰 순서대로 내림차순 정렬(상응하는 eigen vector 함께
(5) d차원으로 줄이고 싶은 경우, 크기 순서대로 d개의 eigen val/vector 선정 / 실질적 차원축소 단계
(6) 선정한 eigen vector들을 concat해서 행렬생성
(7) 준비한 데이터 셋에 concat한 고유벡터의 공간들로 투영(feature data의 행렬에 concat한 행렬을 행렬곱)
- (3)에서 eigen value와 eigen vector는 ‘특이값 분해’(singular value decomposition)를 사용해서 구한다.
주성분 분석 실습
- 와인 데이터를 이용하여 PCA로 차원 축소를 직접 실습
- 차원 축소하기 전과 후 예측 정확도가 어떻게 달라지는지를 확인
- 데이터 불러오기
from sklearn import datasets
raw_wine = datasets.load_wine()
- 피처, 타깃 데이터 지정
X = raw_wine.data
y = raw_wine.target
- train/test data 분할
from sklearn.model_selection import train_test_split
X_tn, X_te, y_tn, y_te = train_test_split(X,y,random_state=1)
- data 표준화
from sklearn.preprocessing import StandardScaler
std_scale = StandardScaler()
std_scale.fit(X_tn)
X_tn_std = std_scale.transform(X_tn)
X_te_std = std_scale.transform(X_te)
- PAC를 통한 차원 축소
from sklearn.decomposition import PCA
# PCA()를 이용하여 모형 설정, 줄이고 싶은 차원수를 '2'로 set up
pca = PCA(n_components=2)
# 표준화된 feature data X_tn_std를 넣어 PCA를 적합시킴
pca.fit(X_tn_std)
# 적합된 PCA 모형을 바탕으로 표준화된 트레이닝 데이터 X_tn_std 데이터를 변형시킨다
X_tn_pca = pca.transform(X_tn_std)
# 동일하게 테스트 데이터 X_te_std 데이터도 변형시킨다
X_te_pca = pca.transform(X_te_std)
- 데이터 차원 축소 확인
print(X_tn_std.shape) # 출력: 133개의 13차원 feature를 가진 원본 data set
print(X_tn_pca.shape) # 출력: 133개의 2차원 feature를 가진 data set으로 차원 축소
print(X_te_std.shape)
print(X_te_pca.shape)
(133, 13)
(133, 2)
(45, 13)
(45, 2)
-
공분산 행렬 확인
- 차원축소에 활용되는 공분산 행렬을 확인가능
print(pca.get_covariance()) # 13X13 matrix이다.
[[ 1.06244198 0.05588975 0.29643474 -0.14674317 0.38769443 0.25079577
0.19779094 -0.10070718 0.17126277 0.44742545 -0.12013532 0.02879752
0.50505224]
[ 0.05588975 0.86510155 0.11906446 0.23837434 0.00721146 -0.39785163
-0.4503856 0.31716671 -0.30728109 0.30100181 -0.42357315 -0.45825394
-0.14345856]
[ 0.29643474 0.11906446 0.72597065 -0.01380654 0.20891722 0.02618151
-0.01633577 0.03209892 0.00824227 0.32033554 -0.17879769 -0.10868048
0.2307792 ]
[-0.14674317 0.23837434 -0.01380654 0.77557799 -0.13456582 -0.4028355
-0.42487887 0.28525095 -0.30301432 0.07431753 -0.28885443 -0.36992936
-0.2952175 ]
[ 0.38769443 0.00721146 0.20891722 -0.13456582 0.82428285 0.22898335
0.19490044 -0.10843832 0.16009666 0.30262412 -0.0453494 0.06951315
0.39222323]
[ 0.25079577 -0.39785163 0.02618151 -0.4028355 0.22898335 1.21144743
0.7122459 -0.47784458 0.50827447 -0.11953458 0.48155509 0.61862946
0.49873766]
[ 0.19779094 -0.4503856 -0.01633577 -0.42487887 0.19490044 0.7122459
1.29615797 -0.51523054 0.53821522 -0.20128733 0.55318211 0.68259141
0.476491 ]
[-0.10070718 0.31716671 0.03209892 0.28525095 -0.10843832 -0.47784458
-0.51523054 0.88680515 -0.36236459 0.17130085 -0.39315908 -0.47274872
-0.29608349]
[ 0.17126277 -0.30728109 0.00824227 -0.30301432 0.16009666 0.50827447
0.53821522 -0.36236459 0.91837171 -0.10951144 0.37402456 0.4731808
0.36224473]
[ 0.44742545 0.30100181 0.32033554 0.07431753 0.30262412 -0.11953458
-0.20128733 0.17130085 -0.10951144 1.11400146 -0.42381722 -0.3369003
0.27449782]
[-0.12013532 -0.42357315 -0.17879769 -0.28885443 -0.0453494 0.48155509
0.55318211 -0.39315908 0.37402456 -0.42381722 1.0843246 0.57894667
0.13493049]
[ 0.02879752 -0.45825394 -0.10868048 -0.36992936 0.06951315 0.61862946
0.68259141 -0.47274872 0.4731808 -0.3369003 0.57894667 1.19451641
0.30839956]
[ 0.50505224 -0.14345856 0.2307792 -0.2952175 0.39222323 0.49873766
0.476491 -0.29608349 0.36224473 0.27449782 0.13493049 0.30839956
1.13948511]]
- Eigen Valaue / Vector 확인
# Eigen values(분산의 크기, 2개)
print(pca.singular_values_)
# Eigen Vectors(2개)
print(pca.components_) # 주성분 벡터들의 집합으로, existing data set에(133X13) covmat으로부터 구한 eigen value가 가장 큰 두개의 eigen vector(13X2)를 concat한 matrix을 곱하면 나오는 벡터들의 집합니다.
[24.81797394 18.31760391]
[[-0.10418545 0.25670612 0.01387486 0.23907587 -0.10470229 -0.4007005
-0.42902734 0.29111343 -0.30307602 0.12127653 -0.31609521 -0.38729685
-0.26283936]
[-0.49018724 -0.1691503 -0.30746987 0.04459018 -0.34837302 -0.07966456
-0.0133774 -0.02498633 -0.0415164 -0.50798383 0.26045807 0.14018631
-0.39850143]]
- Exprienced Variance
# 각 주성분 벡터가 설명하는 분산
print(pca.explained_variance_)
# 분산의 전체 분산 대비 비율 확인
print(pca.explained_variance_ratio_) # 1st PC: 전체 분산의 35% 설명 / 2nd PC: 전체 분산의 19.6% 설명ㄱ
[4.66615023 2.54192889]
[0.35623588 0.19406282]
- 차원 축소 데이터 체크
- 데이터 프레임 형태로 확인 -> 데이터 시각화에 유용하기 때문
# dataframe 형태로 바꾸기 위한 pandas 라이브러리 호출
import pandas as pd
# 차원 축소된 데이터의 column 이름을 정한다
pca_column = ['pca_comp1', 'pca_comp2']
# 차원 축소된 데이터를 데이터 프레임 형태로 나눈다. 위에서 생성한 column name을 옵션으로 입력
X_tn_pca_df = pd.DataFrame(X_tn_pca, columns=pca_column)
# 타깃 데이터도 결합
X_tn_pca_df['target'] = y_tn
# 차원 축소를 통해 만들어진 데이터 확인
X_tn_pca_df.head(135) # 전체 133개라 135 입력해도 133개까지 밖에 출력 안됨
| pca_comp1 | pca_comp2 | target | |
|---|---|---|---|
| 0 | -2.231848 | -0.148603 | 0 |
| 1 | -1.364444 | 0.422617 | 1 |
| 2 | -1.918072 | -2.014682 | 0 |
| 3 | -3.539272 | -2.878394 | 0 |
| 4 | -3.182320 | -2.020041 | 0 |
| ... | ... | ... | ... |
| 128 | 1.995535 | -0.227742 | 2 |
| 129 | 3.785334 | -0.303041 | 2 |
| 130 | 0.530538 | 1.093638 | 1 |
| 131 | 2.625701 | -0.163952 | 2 |
| 132 | -1.269989 | -0.298493 | 0 |
133 rows × 3 columns
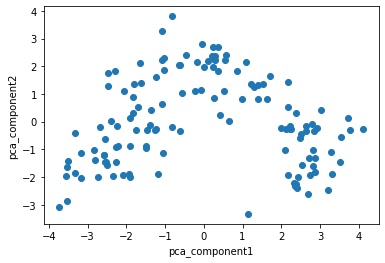
- Label 미적용 PCA 데이터 (타겟 데이터가 없는 경우)
import matplotlib.pyplot as plt
# 각 feature를 시각화 요소로 입력
plt.scatter(X_tn_pca_df['pca_comp1'],
X_tn_pca_df['pca_comp2'],
marker='o')
# x,y축 라벨링
plt.xlabel('pca_component1')
plt.ylabel('pca_component2')
plt.show()
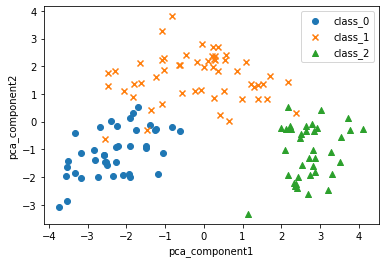
-라벨 적용 PCA 데이터 (타겟 데이터가 있는 경우)
# 시각화할 데이터프레임 지정
df = X_tn_pca_df
# 클래스별로 데이터를 분할
df_0 = df[df['target']==0]
df_1 = df[df['target']==1]
df_2 = df[df['target']==2]
# 클래스별로 분할된 각각의 데이터들에 대해 피처데이터를 분할
# 클래스별 분할된 데이터들의 첫번째 pc를 찾음
X_11 = df_0['pca_comp1']
X_12 = df_1['pca_comp1']
X_13 = df_2['pca_comp1']
# 클래스별 분할된 데이터들의 두번째 pc를 찾음
X_21 = df_0['pca_comp2']
X_22 = df_1['pca_comp2']
X_23 = df_2['pca_comp2']
# 타깃이름을 지정한다
target_0 = raw_wine.target_names[0]
target_1 = raw_wine.target_names[1]
target_2 = raw_wine.target_names[2]
# 총 세가지 와인 클래스에 대해 플롯을 그리므로 플롯코드 세번 반복됨
# marker는 어떤 점을 어떻게 표현할지 정함
# label 옵션으로 어떤 클래스에 해당하는지 표현 가능
plt.scatter(X_11, X_21,
marker='o',
label=target_0)
plt.scatter(X_12, X_22,
marker='x',
label=target_1)
plt.scatter(X_13, X_23,
marker='^',
label=target_2)
plt.xlabel("pca_component1")
plt.ylabel("pca_component2")
# 플롯에 범례추가 (우측 상단)
plt.legend()
plt.show()
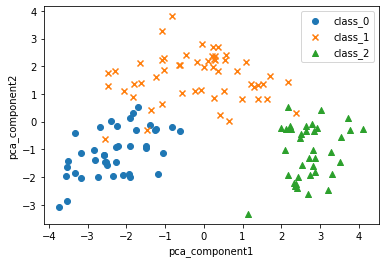
- 반복문 이용한 시각화
df = X_tn_pca_df
markers = ['o', 'x', '^']
for i, mark in enumerate(markers):
df_i = df[df['target']==i]
target_i = raw_wine.target_names[i]
X1 = df_i['pca_comp1']
X2 = df_i['pca_comp2']
plt.scatter(X1, X2,
marker=mark,
label=target_i)
plt.xlabel("pca_component1")
plt.ylabel("pca_component2")
plt.legend()
plt.show()
- PCA 적용 이전 데이터학습
from sklearn.ensemble import RandomForestClassifier
# RandomForest 모형을 지정. depth는 2이고 랜덤시드값이 0인 모델 설정
clf_rf = RandomForestClassifier(max_depth=2, random_state=0)
# 해당 모형에 데이터를 넣어 적합
clf_rf.fit(X_tn_std,y_tn)
# RandomForest 예측값 확인
pred_rf = clf_rf.predict(X_te_std)
print(pred_rf)
[2 1 0 1 0 2 1 0 2 1 0 0 1 0 1 1 2 0 1 0 0 1 2 0 0 2 0 0 0 2 1 2 2 0 1 1 1
1 1 0 0 1 2 0 0]
- PCA 적용 이전 데이터 예측 정확도
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_te, pred_rf)
print(accuracy)
0.9777777777777777
- PCA 적용 후 데이터 학습
from sklearn.ensemble import RandomForestClassifier
clf_rf_pca = RandomForestClassifier(max_depth=2, random_state=0)
clf_rf_pca.fit(X_tn_pca, y_tn)
pred_rf_pca = clf_rf_pca.predict(X_te_pca)
- PCA 적용 후 데이터 예측 정확도
accuracy_pca = accuracy_score(y_te, pred_rf_pca)
print(accuracy_pca)
0.9555555555555556
PCA 적용 후의 정확도와 적용 전의 정확도 비교를 통한 해석
- 2%가량 줄어든 정확도를 보여준다.
이유는 명백하다. 이전에는 13차원의 feature를 가진 data였는데 이제는 2차원의 feature를 가진 데이터로 차원 축소를 했기때문이다. 그러나, 그 감소율은 그에 비해 매우 적은 편이다. 학습 비용을 고려할 때, 차원 축소를 이용하면 학습 비용 대비 정확도 감소는 매우 작기에 상당히 ‘효율적’임을 알 수 있다. - 이렇듯 실제로, 고차원 데이터의 경우, 시스템 리소스가 부족해 학습이 어려운 경우가 비일비재한데, 차원 축소를 통해 해당 문제를 해결하게 된다.